
Hướng dẫn dùng Random Forest trên Sklearn


Step 1:
Step 2: chuẩn bị dataset (Iris dataset)
info of dataset
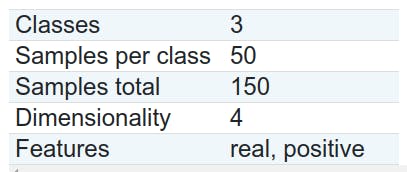
code bên dưới sẽ làm nhiệm vụ tạo dataframe của dataset, split ra 2 bộ train/test và đổi thành dạng Array.
#%%
# load dataset ( we will use iris dataset)
bunch = sklearn.datasets.load_iris()
# extract dataset
data = bunch['data']
target = bunch['target']
frame = bunch['frame']
target_names = bunch['target_names']
feature_name = bunch['feature_names']
# create dataframe
df = pd.DataFrame(data, columns=["fea_1", "fea_2", "fea_3", "fea_4"])
df['target'] = target
# split train/test
df_train = df.sample(frac=0.7, random_state=0)
df_test = df.drop(df_train.index)
# create train_label, train_target array
df_train_tmp = df_train.copy()
train_target = np.array(df_train_tmp.pop('target'))
train_label = df_train_tmp.__array__()
# create test_label, test_target
df_test_tmp = df_test.copy()
test_target = np.array(df_test_tmp.pop('target'))
test_label = df_test_tmp.__array__()
Tìm hiểu về config của Decision Tree trên sklearn
from sklearn import tree
clf_config = tree.DecisionTreeClassifier(
criterion="gini",
splitter="best",
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0,
min_impurity_split=0,
class_weight=None,
ccp_alpha=0,
)
chúng ta sẽ đi tìm hiểu về các parameter trong này, mỗi parameter mình sẽ cho điểm về mức độ quan trọng mà mọi người cần lưu ý, ví dụ splitter (3/5)
1. criterion (5/5)
quantdare.com/decision-trees-gini-vs-entropy
criterion sẽ dùng để đánh giá xem feature nào sẽ được làm root, và kế tiếp sau đó theo mức độ ưu tiên
hiện tại có 2 tiêu chuẩn để đánh giá là gini và entropy
Gini:
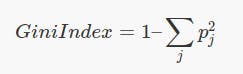 Entropy:
Entropy:
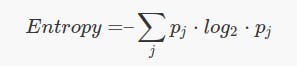
ưu điểm: Gini nhanh hơn vì Entropy phải sử dụng hàm log trong công thức
tuy nhiên, bạn có thể build cả 2 mô hình để xem thử criterion nào hiệu quả hơn
khuyên dùng: Gini
2. Splitter (1/5)
Splitter dùng để hỏi bạn xem bạn có muốn split internal node theo 2 cách best hoặc random không
cứ để mặc định là best thôi, không thì 1 đống setting phía sau coi như bị giảm tác dụng.
3. max_depth (4/5)
`The maximum depth of the tree. If None, then nodes are expanded until
all leaves are pure or until all leaves contain less than
min_samples_split samples.`
thông thường, decision tree sẽ tạo nhánh cho tới khi nào gini của child node lớn hơn gini của parent node ( nghĩa là việc chia nhánh không hiệu quả bằng việc để yên như cũ ) thì lúc đó parent node sẽ dừng tại đó, lúc này sẽ gọi là leaf hay leaf node
nếu set max_depth = None, thì tree sẽ chạy như đã nói ở trên, hoặc nếu ta set min_samples_split thì nó sẽ dừng khi min_samples_split thỏa điều kiện.
min_samples_split sẽ nói sau
còn nếu set max_depth = int , tree sẽ chia nhánh cho tới khi đạt tới ngưỡng đã set
4. min_samples_split (2/5)
thông số này dùng để kiểm soát node được split, phải có ít nhất 1 số lượng sample trong đó. ví dụ set min_sample_split = 50 thì nếu 1 node muốn split 1 child node có 49 samples trong đó cũng sẽ không thực hiện được
5. min_samples_leaf (2/5)
tương tự, số này dùng để kiểm soát samples trong leaf, nếu 1 node có ít hơn số lượng sample được set trong min_sample_leaf thì node đó chắc chắn không thể là leaf node
6. min_weight_fraction_leaf (2/5)
kiểm soát weight của các samples trong leaf ( mình không hiểu lắm, cứ để default thôi, không quan trọng)
7. max_features (4/5)
đây là 1 thông số quan trọng, dùng để kiểm soát số lượng features dùng để split mỗi lần
ví dụ, khi bạn có 10 features, tuy nhiên max_features = 5, thì mỗi lần split, thuật toán chỉ bốc 5 feature ra để đánh giá thôi.
max_feature dùng để tunning trong thuật toán Random Forest, còn nếu chỉ dùng Decision Tree, bạn có thể đơn giản là set max_feature = None, nghĩa là dùng toàn bộ features cho mỗi lần split.
8. random_state (2/5)
random_state dùng để random cho thằng max_feature. như mình đã nói ở trên, với 10 feature, max_feature = 5 thì mỗi lần split, thuật toán sẽ bốc random 5 feature để đánh giá, còn cách bốc random như thế nào thì tham số random_state sẽ giải quyết
9. max_leaf_nodes (3/5)
kiểm soát số lượng leaf node tối đa trong 1 decision tree.
ví dụ set max_leaf_nodes = 5 thì trong tree đó tối đa chỉ có 5 leaf node
1 thông số cũng khá quan trọng, vì leaf node chính là kết quả của decision tree. tuy nhiên cũng khá abstract nên có thể dùng làm thông số để tunning.
10. min_impurity_decrease (2/5)
thông số này khá giống thông số early stopping trong mấy thuật toán gradient descent. nghĩa là nếu child node không giảm gini ( hoặc entropy) được 1 lượng là bao nhiêu đó, thì nó sẽ không cho split.
lượng đó được quy định trong min_impurity_dcrease
11. min_impurity_split (2/5)
không khác lắm cái min_impurity_decrease ( nên bỏ qua tham số này và chỉ dùng tham số min_impurity_descrease ở trên)
12. class_weight (3/5)
set trọng số cho mỗi class. một thông số cũng khá quan trong, có thể cân nhắc tunning trong 1 số trường hợp ví dụ như có sự chênh lệch về số lượng sample mỗi class, hoặc bạn hiểu được 1 số class quan trọng hơn chẳng hạn.
tuy nhiên hầu hết trường hợp mình sẽ set = "balance"
bạn có thể đọc thêm về cách set trọng số trong document của sklearn decision tree đại khái là nó kiểu như này:
[{1:1}, {2:5}, {3:1}, {4:1}]
13: ccp_alpha (?/5)
tham số mới được thằng sklearn thêm vào, chưa hiểu lắm cách hoạt động, nên set default lun.
fit and test
#### try decision tree with config
clf_config = tree.DecisionTreeClassifier(
criterion="gini",
splitter="best",
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0,
min_impurity_split=0,
class_weight=None,
ccp_alpha=0,
)
clf.fit(train_label, train_target)
clf.score(test_label, test_target)
ok mình sẽ để setting như trên và fit thử với bộ train set, sau đó kiểm tra với test set
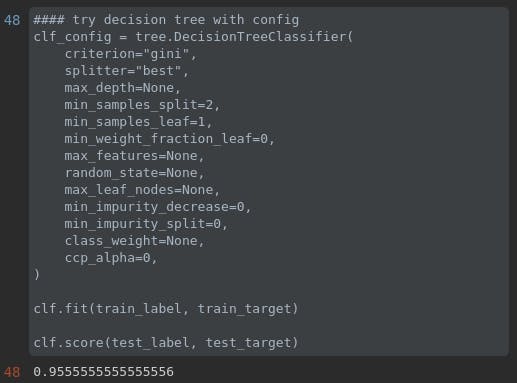
ta có kết quá là 0.95, nghĩa là 95%
bạn có thể dùng GridSearchCV của thằng sklearn để thử tuning các tham số trên, khả năng là sẽ cao hơn 95% đấy !
Tìm hiểu về config của Random Forest trên sklearn
from sklearn.ensemble import RandomForestClassifier
clf_rand_forest = RandomForestClassifier(
n_estimators=100,
criterion="gini",
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0,
max_features="auto",
max_leaf_nodes=None,
min_impurity_decrease=0,
min_impurity_split=None,
bootstrap=True,
oob_score=False,
n_jobs=None,
random_state=None,
verbose=0,
warm_start=False,
class_weight=None,
ccp_alpha=0,
max_samples=None,
)
vì random forest thực chất chỉ là tập hợp của nhiều decision tree, nên đa số các tham số xuất hiện ở decision tree sẽ có trong này, mình sẽ đi nhanh qua những tham số nào bị trùng lặp
1. n_estimators (5/5)
số lượng tree trong forest. thông số quan trọng để tuning model
2. criterion (5/5)
xem ở phần decision tree
3. min_samples_split (2/5)
xem ở phần decision tree
4. min_samples_leaf (2/5)
xem ở phần decision tree
5. min_weight_fraction_leaf (2/5)
xem ở phần decision tree
6. max_features (4/5)
xem ở phần decision tree
7. max_leaf_nodes (2/5)
xem ở phần decison tree
8. min_impurity_decrease (2/5)
xem ở phần decision tree
9. bootstrap (1/5)
bootstrap là 1 tập dataset tuy nhiên không đầy đủ
ví dụ tập data của bạn có 50 samples KHÔNG TRÙNG LẶP. Ta sẽ lấy ra 2/3 (hoặc 1 số lượng nào đó) các samples để tạo thành 1 tập data mới gọi là bootstrap.
tập bootstrap có đặc điểm là các sample CÓ THỂ TRÙNG LẶP NHAU.
tham số có giá trị boolean, dùng hoặc không dùng boostrap
mặc dù boostrap là 1 trong những khái niệm quan trọng nhất của Random Forest, tuy nhiên vì lí do đó mà hầu như mọi trường hợp mình đều sẽ set bootstrap = True, nên tham số này gần như mặc định là vậy
10. oob_score (5/5)
oob trong oob_score nghĩa là out of bags . Ý nói đến các sample bị loại khỏi bootstrap. như vậy khi ta build random forest trên tập bootstrap đó, các oob này có thể được dùng làm 1 tập data để đánh giá kết quả của random forest đó.
tham số boolean, dùng hoặc không dùng out of bag để đánh giá kết quả của từng tree.
mặc dù sklearn mặc định là False, tuy nhiên mình thường set oob_score = True để việc đánh giá chính xác hơn.
11. n_jobs (4/5)
cái này mình hiểu cơ bản là vầy
ví dụ khi bắt đầu build Random forest, ta sẽ cần tạo các bootstrap trước. giả sử ta tạo 10 bootstrap
sau đó mỗi bootstrap sẽ đi làm nhiệm vụ tạo các decision tree, như vậy n_jobs là tham số kiểm soát xem bao nhiêu bootstrap chạy song song nhau.
nếu tất cả đều chạy parallel thì model sẽ chạy nhanh hơn
12. random_state (2/5)
giống với ở Decision Tree, ngoài ra còn kiểm soát random của bootstrap
13. verbose (1/5)
dùng để mô tả chi tiết hoạt động của model
14. warm_start (4/5)
set = True sẽ giữ lại những gì đã được học, có thể dùng để đi tuning tiếp mà không tốn nhiều thời gian, phù hợp cho tuning dùng grid search
ví dụ, ta dùng grid search cv để tìm ra model tốt nhất với 5 phương án:
n_estimators = [10, 20, 30, 40 ,50]
như vậy nếu ta không dùng warm_start, với mỗi phương án n_estimators, model sẽ phải đi train lại từ đầu, rất tốn thời gian
nếu dùng warm_start, model sẽ lưu lại những giá trị của model trước
ví dụ sau khi train xong model với n_estimators = 10, khi train tiếp với n_estimators = 20, model sẽ chỉ add thêm 10 trees mới vào, còn 10 trees cũ vẫn giữ của model trước đó.
15. class_weight (3/5)
tương tự như ở Decision Tree
16. ccp_alpha (?/5)
tương tự như ở Decision Tree
max_samples (4/5)
số lượng sample lấy ra từ tập data để bỏ vào bootstrap.
khuyến khích dùng dạng float giá trị từ (0,1) , đọc document của random forest sklearn để biết thêm cách dùng
fit and test
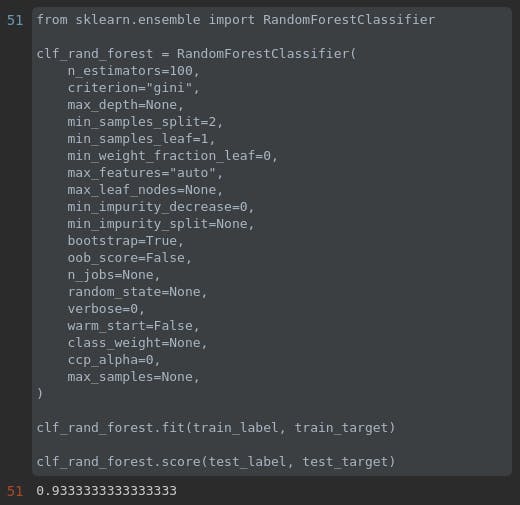
dựa vào kết quả default, ta thấy thậm chí random forest cho kết quả còn tệ hơn là build 1 decision tree đơn thuần :)
giải thích:
có thể vấn đề ở đây nằm ở bootstrap, ta hiểu đơn giản rằng, Decision tree thực chất là Random forest mà set bootstrap = False.
mặc dù thực tế random forest sau khi chia bootstrap, thuật toán sẽ chọn tiếp random chỉ 1 số các features để build tree, để nhằm mục đích tạo ra nhiều tree hơn, nếu mà dùng toàn bộ feature và set bootstrap = False thì Random forest chỉ có đúng 1 cây duy nhất, đó chính là Decision Tree nguyên bản.
như vậy nếu ta set bootstrap = False, v thì có khả năng cao là 1 trong 100 tree kia sẽ ít nhất là có tree giống y chang với decision tree nguyên bản, nghĩa là ít nhất sẽ >= 95%.
ta tiến hành thử bằng cách set bootstrap = False và train lại model:
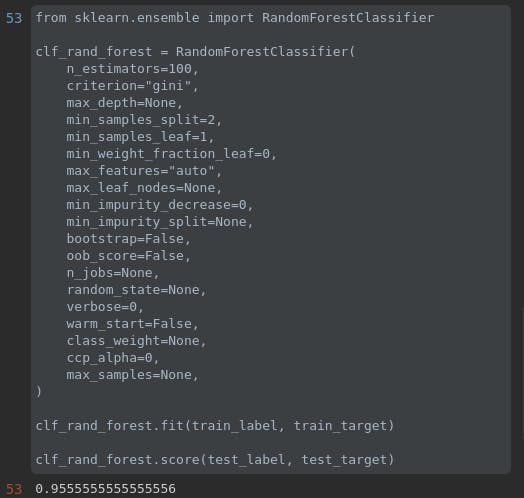
ta thấy tỉ lệ lên 95%. giống với tỉ lệ của bên Decision Tree ta train hồi nãy. có nghĩa là trong 100 cây đó đã có 1 cây trùng với decision tree ta train ban đầu. Và cây đó cũng là cây có kết quả tốt nhất :)
=> kết luận: không phải lúc nào thuật toán phức tạp cũng cho ra kết quả tốt hơn. chúng ta cần nắm và phối hợp linh hoạt các thuật toán với nhau để đem lại 1 phương án phù hợp nhất.