



List necessary tools:
- java 8
- apache hadoop
- apache spark
- luigi
- apache hive
*In this instruction, we will have 2 machine:
- master
- slave
INSTALL IN ALL MACHINE
these install have to do in all machine
check ip of your machine by using ifconfig or ip addr show
go to :
sudo nano /etc/hosts
add these:
<master ip> master
<slave ip> slave
I. Java 8
Because hadoop and spark run on java 8, so that we will install java first.
The easiest way to install java is using SDKMAN:
$ curl -s "https://get.sdkman.io" | bash
check sdk
$ sdk version
check list java version SDK support
$ sdk list java
================================================================================
Available Java Versions
================================================================================
12.ea.20-open
* 11.0.1-zulu
* 11.0.1-open
10.0.2-zulu
10.0.2-open
9.0.7-zulu
9.0.4-open
8.0.192-zulu
8.0.191-oracle
> + 8.0.181-zulu
choose java version 8 ( I use zulu )
$ sdk install java 8.0.192-zulu
check java
$ java -version
add java enviroment
(u can set in either .bashrc, .profile or enviroment. Reccomment .bashrc)
export JAVA_HOME=/usr/lib/jvm/8.0.282-zulu
export PATH=$PATH:export PATH=$PATH:/usr/lib/jvm/8.0.282-zulu/bin
II. Install SSH, PDSH
ref: thachpham.com/linux-webserver/huong-dan-ssh..
we will use SSH, PDSH to connect multi machine for hadoop and spark
sudo apt-get install ssh
and then install pdsh
sudo apt-get install pdsh
add path to .bashrc
export PDSH_RCMD_TYPE=ssh
try ssh to localhost:
ssh localhost
II. Hadoop
Note that I follow most from this tutorial below, you can check this video along with my post.
#%[youtube.com/watch?v=KN6uzfQ42zE&t=117s]
INSTALL IN ALL MACHINE
add this to .bashrc. this is for quick access to hadoop
export bh="/usr/local/bigdata/hadoop"
you can access by using
cd $bh
Step 0 : turn off firewall in all machine
https://phoenixnap.com/kb/how-to-enable-disable-firewall-ubuntu
check status:
sudo ufw status verbose
disable:
sudo ufw disable
enable:
sudo ufw enable
reset:
sudo ufw reset
Step 1
create folder bigdata in local: we will note create folder bigdata in user directory, but in system directory instead
$ mkdir /usr/local/bigdata
create folder hadoop:
$ mkdir /usr/local/bigdata/hadoop
Step 2
add authority to bidata folder
sudo chown <username>:root -R /usr/local/bigdata/
check
drwxr-xr-x 4 <username> root 4096 Thg 2 14 01:00 bigdata
Step 2
we will add some path to hadoop:
open .bashrc and paste this:
export HADOOP_HOME="/usr/local/bigdata/hadoop"
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_STREAMING=$HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-3.2.2.jar
Step 3:
now go to website hadoop.apache.org
download the tar file ( I use version 3.2.2) extract it
tar -zxvf ~/Downloads/hadoop-3.2.2.tar.gz
move file to bigdata folder
mv ~/Downloads/hadoop-3.2.2/* /usr/local/bigdata/hadoop
Step 4: CONFIG ENVIRONMENT HADOOP
note: you can just config hadoop environment in master machine, and then copy its setting to slaves by using:
scp /usr/local/bigdata/hadoop/etc/hadoop/* <user-name>@slave:/usr/local/bigdata/hadoop/etc/hadoop/
cd to /usr/local/bigdata/hadoop/etc/hadoop/. this is the config folder of hadoop
* hadoop-env.h
find JAVA_HOME , change to:
JAVA_HOME=/usr/lib/jvm/8.0.282-zulu
* core-site.xml
add these:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.proxyuser.dataflair.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.dataflair.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.server.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.server.groups</name>
<value>*</value>
</property>
</configuration>
* hdfs-site.xml
add these:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/bigdata/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/bigdata/hadoop/tmp/dfs/data</value>
</property>
</configuration>
note: ditectory tmp is where hdfs store data, it will auto create since we format namenote by using <hadoop>/bin/hdfs namenode -format
* mapred-site.xml (since we use spark to manipulate data, we don't need map-reduce)
add these:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
* yarn-site.xml
add these:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME>
</property>
</configuration>
run this to add worker
sudo nano /usr/local/bigdata/hadoop/etc/hadoop/workers
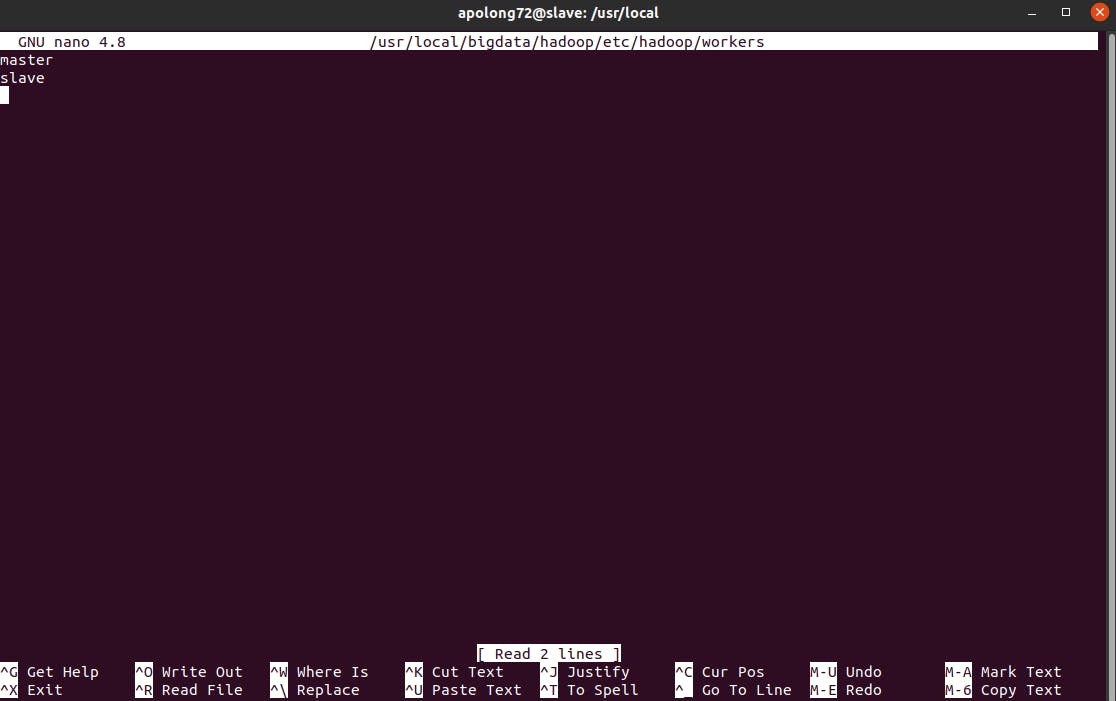
Step 5:
run this:
/usr/local/bigdata/hadoop/bin/hdfs namenode -format
this will create folder tmp as well format everything.
INSTALL IN MASTER NODE
create ssh key
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
add content of public key to auth keys
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
add mod 600 to auth keys
chmod 0600 ~/.ssh/authorized_keys
note: disable password auth since we will use ssh key to connect machines
go to /etc/ssh/sshd_config, find and set these:
PasswordAuthentication no
UsePAM no
then, try to connect to master
ssh master
connect to slave
run this. it will copy public key in master to slave
ssh-copy-id <slave user>@slave
if user have password, type it.
then, try to connect to slave using
ssh slave
go to
sudo nano /etc/hostname
add these
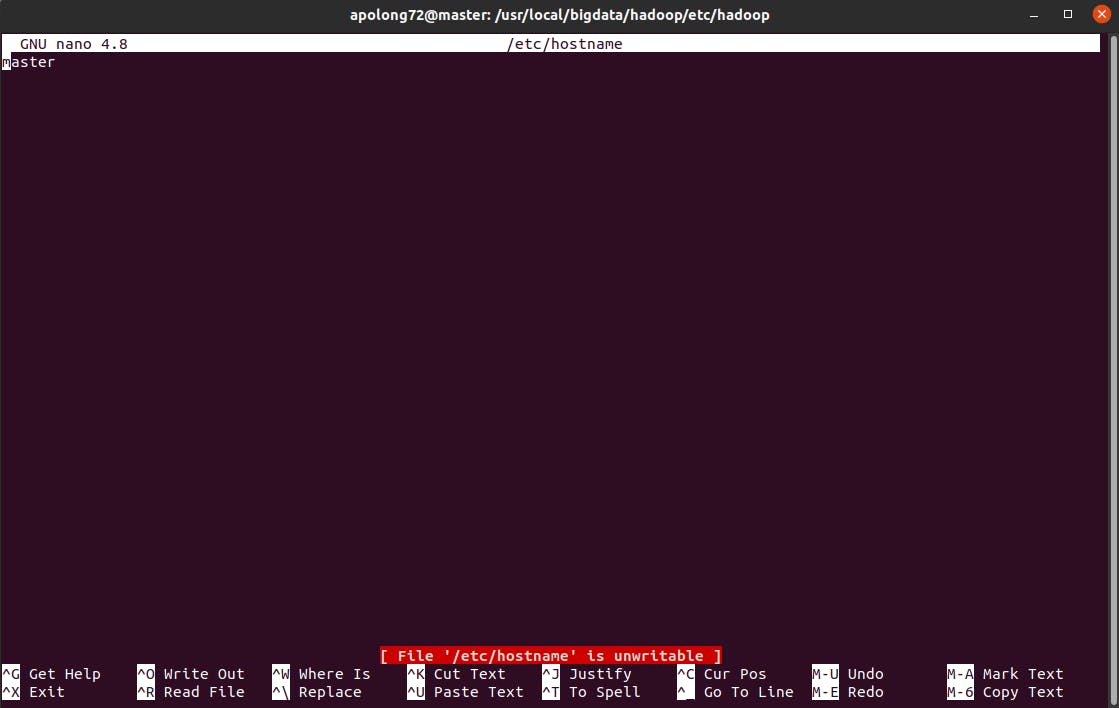
INSTALL IN SLAVE NODE
go to
sudo nano /etc/hostname
add these
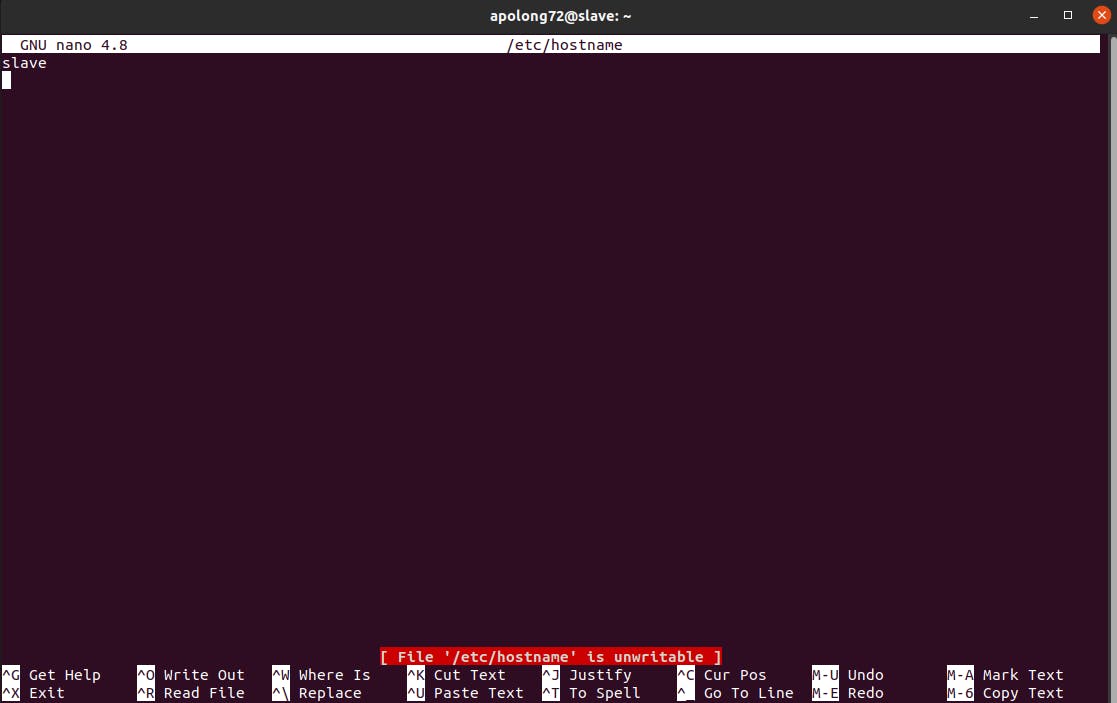
Lastly, in MASTER try to run hdfs:
go to hadoop directory
cd $bh
you can run manually by using:
hdfs:
sbin/start-dfs.sh
yarn:
sbin/start-yarn.sh
or just run auto by using:
sbin/start-all.sh
note: if you have any problem go to
$bh/logs/<file-that-describe-component-that-have-error.log>
you can go to and inspect error in it
afterall, you should see that
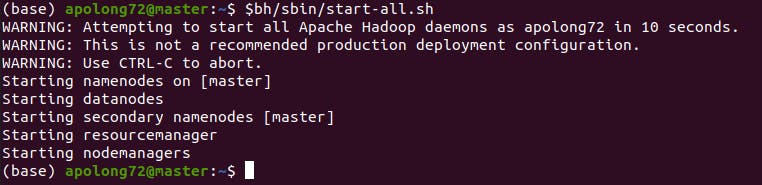
check if everything is ok by using jps
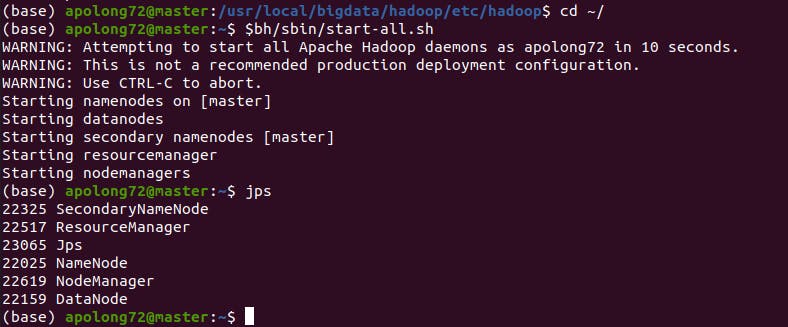
go to SLAVE by using
ssh slave
and run jps
you should see this
in MASTER, go to http://master:9870
you can check if all node worked:

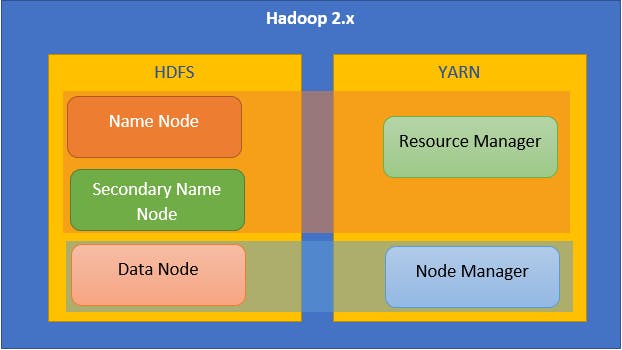
so to summerize, namenode is a master node that only appear on MASTER machine only, in SLAVE machine we only see datanode (aka slave node) and node manager
hadoop work like this:
III.SPARK
next, we will install spark
INSTALL IN ALL MACHINE
step 1:
go to https://spark.apache.org/downloads.html and download suitable version
step 2:
create folder /usr/local/bigdata/spark/ and extract files to it
go to .bashrc and add this
SPARK_HOME="/usr/local/bigdata/spark"
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
and this (use for quick access spark folder)
export bs="/usr/local/bigdata/spark"
step 3:
go to:
cd $bs/conf
run this (copy templates to new file in order to edit it)
cp spark-env.sh.template spark-env.sh
cp slaves.sh.template slaves.sh
then edit spark-env.sh and add these:
export SPARK_MASTER_HOST='<MASTER-IP>'
export JAVA_HOME=<Path_of_JAVA_installation>
then edit slaves.sh and add these: ( this is the names we map to machines ip above)
master
slave
step 4:
in MASTER machine, run this:
$bs/sbin/start-all.sh
note: you can go to $bs/logs to check if any error occurs
if everything work fine, you should see this:
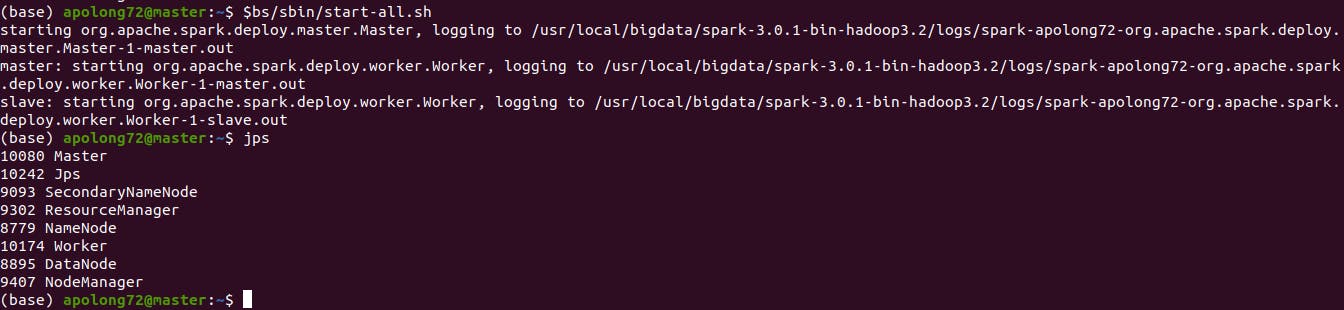
ssh to slave:
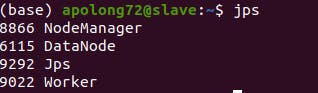
you can see that in SLAVE machine, occur worker node.
go to http://master:8080 (master port)
you should see something like this
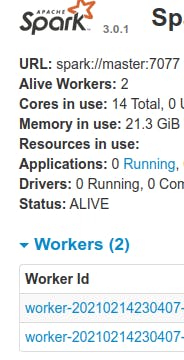
~~~~~~~~~~~~~~
reference:
hadoop:
set up hadoop multi node
medium0.com/@jootorres_11979/how-to-set-up-..
scp
linuxize.com/post/how-to-use-scp-command-to..
spark:
medium0.com/ymedialabs-innovation/apache-sp..